Why Use Go for Data Science?
Building scalable, high-performance, data-intensive applications is hard. It can involve many languages in a complex software stack. Such environments are hard to implement and hard to maintain over time.
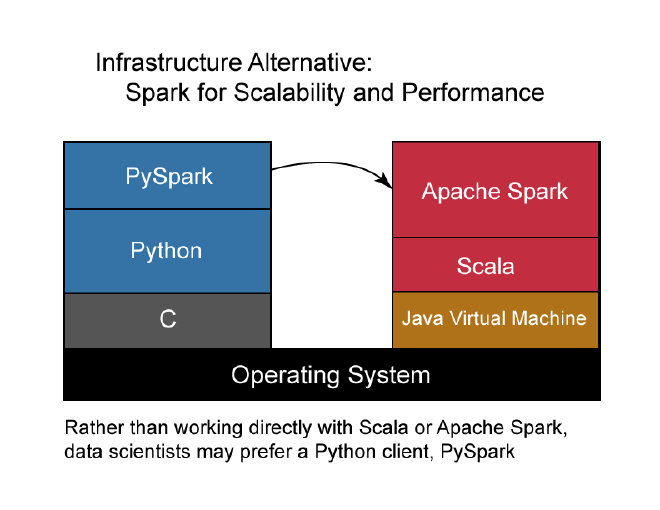
The figure above shows the Apache Spark software stack at the right. Spark depends on Scala, which depends on the Java Virtual Machine (JVM).
While Spark is well-suited for building data-intensive applications, most data scientists are not fluent in Scala or Java. So, they turn to PySpark, a Python client to Spark. This adds the software stack at the left of the figure. PySpark depends on Python, which depends on C.
There must be a better way to build data science applications.
References #
- Karau, Holden, Andy Konwinski, Patrick Wendell, and Matei Zaharia. 0215. Learning Spark: Lightning-Fast Data Analysis. Sebastopol, CA: O’Reilly. [ISBN-13: 978-1-449-35862-4]
- Kleppman, Martin. 2017. Designing Data-Intensive Applications: The Big Ideas behind Reliable, Scalable, and Maintainable Systems. Sebastopol, CA: O’Reilly. [ISBN-13: 978-1-449-37332-0]
- Ryza, Sandy, Uri Laserson, Sean Owen, and Josh Wills. 2015. Advanced Analytics with Spark: Patterns for Learning from Data at Scale. Sebastopol, CA: O’Reilly. [ISBN-13: 978-1-491-91276-8]
Back to the Languages for Data Science page.